

Wat is Azure Data Factory Data Flow? Is Azure Data Factory Data Flow de toekomst? Hoe is het ontstaan? Wanneer en bij wie passen wij dit toe? Dit zijn vragen die in deze blog beantwoord worden. In het anderhalve jaar dat ik inmiddels bij Valid werk heb ik al heel wat verschillende werkwijzes meegemaakt. Om te leren wat Azure Data Factory Data Flow (ADF-DF) ons als BI-team precies kan brengen is het belangrijk om de transitie in werkwijze hiernaartoe te begrijpen.
Werkwijze 1: SSIS in combinatie met een lokale SQL server/lokale databases
Op het moment dat ik bij Valid kwam werken maakten we al gebruik van Virtual Machines in plaats van traditionele dedicated servers. Op deze Virtual Machine werden de databases aangemaakt die nodig waren voor ons Valid BI framework. Het verplaatsen van data doen wij door gebruik te maken van SQL Server Integration Services (SSIS). Dit is een van de componenten van SQL Server Data Tools (SSDT), een add-on binnen Visual Studio. In SSIS maken we zogenaamde ‘packages’ en hierin geven we aan van welke bron de data verplaatst moet worden naar welke bestemming. Daarnaast geven we ook aan wat er met de data dient te gebeuren, bijvoorbeeld welke transformaties er plaats dienen te vinden. Deze packages worden vervolgens naar de lokale SQL server die op de Virtual Machine draait gedeployed.
Werkwijze 2: SSIS in combinatie met een lokale SQL server/Azure SQL Databases
De eerste verandering die ik heb meegemaakt was het vervangen van lokale databases door Azure SQL databases. We maken gebruik van vijf databases; drie databases met daarin klantdata en twee databases met daarin de configuratie van het framework. De drie databases met data hebben we omgezet naar Azure SQL databases. Het grote voordeel van Azure SQL databases was de mogelijkheid om op- en af te schalen qua capaciteit. Daarnaast is het ook makkelijker voor andere Azure services om deze databases te benaderen. De SSIS packages worden hier nog naar de lokale SQL server op de VM gedeployed.
De volgende verandering maakt gebruik van Azure Data Factory. Om deze verandering beter te begrijpen is eerst een toelichting van Microsoft ADF nodig.
Wat is Azure Data Factory?
Microsoft heeft ADF ontworpen om de integratie van verschillende bronsystemen zo makkelijk mogelijk te maken voor developers. Momenteel maken wij gebruik van SQL Server Integration Services (SSIS) om data te verwerken. ADF is, net als SSIS, een platform, maar hiermee is het mogelijk om zowel on-premise data als cloud data te verwerken. Azure Data Factory maakt gebruik van de volgende componenten:
Linked service
Een linked service is een connectie naar een bestaande databron. Dit kan bijvoorbeeld een Azure SQL Database zijn, een blob storage of een data lake.
Dataset
Een dataset is hetgeen wat daadwerkelijk de data bevat. Een dataset dient altijd gekoppeld te worden aan een linked service. Stel dat de linked service een connectie is naar een Azure SQL Database, dan zou een dataset een tabel in deze database kunnen zijn.
Pipeline
Een pipeline is een groepering van meerdere activiteiten die samen een taak uitvoeren. De activiteiten binnen een pipeline definiëren de acties die worden uitgevoerd op de data. Een pipeline kan bijvoorbeeld bestanden kopiëren, uitlezen en laden in een bestemming. Ook kan een pipeline een data flow aanroepen met behulp van Azure Data Factory Data Flow.
Integration Runtime
Wij gebruiken een integration runtime ter vervanging van een integration catalog. Dit is de plek waarin we de hiervoor beschreven ‘packages’ naartoe kunnen deployen. Een integration runtime is onderwater niet meer dan een Virtual Machine, maar het grootste voordeel hiervan is dat je zelf geen beheer meer hebt over een Virtual Machine. Dit scheelt natuurlijk ook in de kosten, aangezien Virtual Machines over het algemeen vrij prijzig zijn.
Werkwijze 3: SSIS in combinatie met Azure Data Factory Integration Runtime
De volgende werkwijze maakt gebruik van SSIS om de packages te ontwerpen, maar deze packages worden vervolgens deployed naar een Integration Runtime binnen Azure Data Factory. Het voordeel hiervan is dat er geen Virtual Machine meer nodig is. De enige voorwaarde hieraan is dat alle databases dienen omgezet te worden naar Azure SQL databases, zodat deze door andere Azure services benaderd kunnen worden.
De laatste werkwijze maakt gebruik van Azure Data Factory Data Flow. Momenteel zoeken we intern uit of het gebruik voordelig is voor onze klanten en of we ons huidige framework kunnen aanpassen.
Wat is Azure Data Factory Data Flow?
Azure Data Factory is nu al een tijdje op de markt. Voorheen was het mogelijk om data te verplaatsen van locatie A naar locatie B. Daarnaast was het ook mogelijk om data uit bron A te extraheren en in bron B te laden, ook wel EL (Extract and Load) genoemd. Hetgeen wat wij als developers nog misten was de ‘Transformation’ van data. Het is mogelijk om de transformaties binnen SQL Server uit te voeren, maar het transformeren van data binnen Azure Data Factory zou een mooie toevoeging zijn. Het belangrijkste voordeel hiervan is dat naast een cloud solution het ook overzichtelijker wordt en dus ook gebruiksvriendelijker.
SSIS is de huidige tool die wij gebruiken voor het verplaatsen en transformeren van data. Met Azure Data Factory Data Flow kunnen wij hetzelfde uitvoeren, maar dan serverless. SSIS wordt gezien als een on-premise solution en maakt gebruik van de processing power van een server of Virtual Machine. Microsoft heeft zijn best gedaan om de functionaliteiten van SSIS in Azure Data Factory Data Flow te verwerken. Voor een overzicht en vergelijking van SSIS activites en ADF-DF activities kijk hier.
Ten opzichte van SSIS maakt ADF-DF gebruik van Azure Databricks.
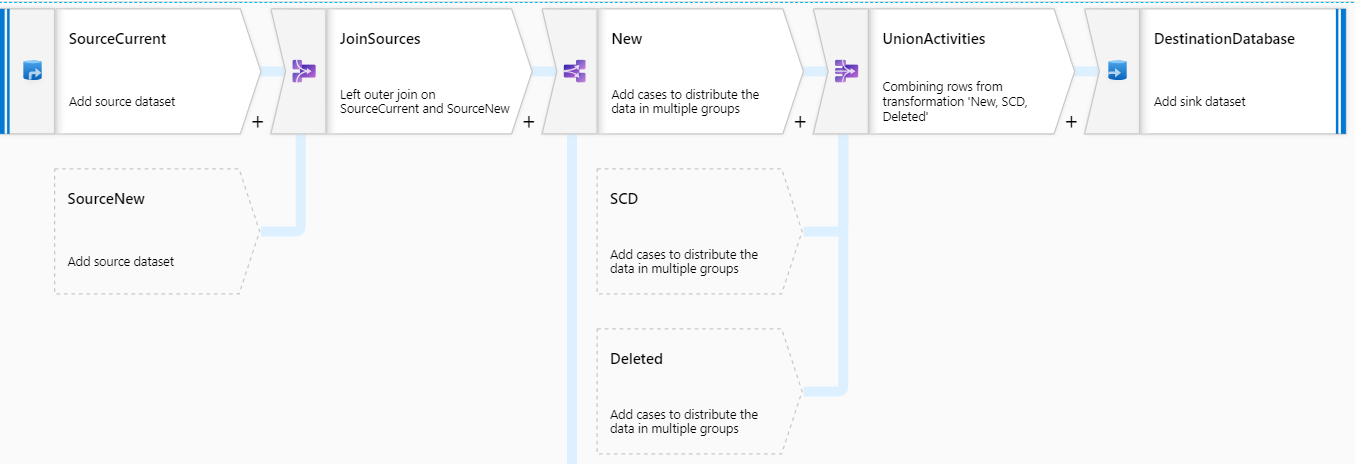
Databricks
Azure Databricks is een op Apache Spark gebaseerd analyseplatform. Apache Spark maakt gebruik van Spark clusters waarmee het mogelijk is om meerdere processen gelijktijdig te draaien. Hierdoor krijgt het proces een enorme performance boost. Bij Azure Databricks betaal je enkel op het moment dat de cluster aan het draaien is. Het is mogelijk om zelf te configureren hoe lang een cluster dient te draaien wanneer er geen activiteit plaatsvindt. Standaard zal de cluster opstarten wanneer hier een aanvraag voor gedaan wordt. Het is sinds kort ook mogelijk om een cluster ‘warm’ te houden. Dit is een handige functionaliteit aangezien het gemiddeld 10 minuten duurt voordat een cluster opgestart is.
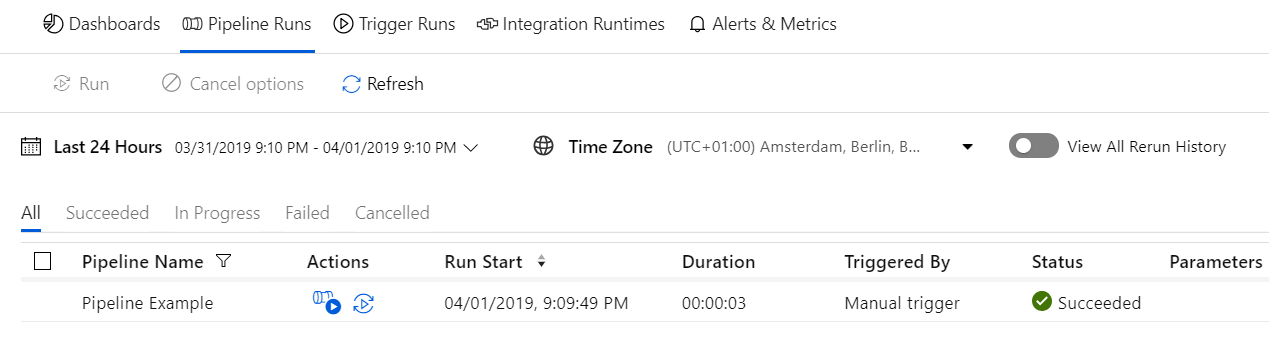
Monitoring
Het is mogelijk om de processen binnen Azure Data Factory te monitoren. Zo is het mogelijk om te zien of het proces succesvol heeft gelopen en daarnaast ook hoeveel regels er per data flow verwerkt zijn.
Werkwijze 4: Azure Data Factory Data Flow
Azure Data Factory Data Flow zou een mooie toevoeging zijn voor alle organisaties. Zoals eerder vermeld zijn we momenteel intern aan het onderzoeken of we dit ook in kunnen gaan zetten bij onze klanten. We kijken of we ons huidige framework dat op SSIS gebaseerd is ook na kunnen bouwen in Azure Data Factory. Daarnaast doen we ook onderzoek naar de kosten die ADF en Databricks met zich meebrengen om ook een groot voordeel naar onze klanten te brengen.
Momenteel vind ik het nog te vroeg om gebruik te maken van Azure Data Factory Data Flow. Dit komt vooral doordat er nog veel SSIS functionaliteiten missen binnen Azure Data Factory Data Flow. Daarnaast maken we momenteel binnen SSIS gebruik van handige technieken, waaronder de scripting tool. Hiermee kunnen we snel packages genereren aan de hand van metadata en dit is iets wat we nog niet hebben gemaakt binnen Azure Data Factory. Als laatste dienen we nog te onderzoeken wat ADF-DF precies kost. Zoals eerder vermeld maakt ADF-DF gebruik van Databricks en zitten er kosten verbonden aan het draaien van het cluster.
Tot slot
Al met al belooft Azure Data Factory veel goeds voor de toekomst. Het is momenteel al mogelijk om de Virtual Machines uit te faseren, maar het werken zonder SSIS laat nog even op zich wachten. We zullen dus nog even moeten wachten voordat SSIS door Data Flow vervangen kan worden, omdat er momenteel een aantal belangrijke componenten niet voorkomen in Data Flow. Daarnaast dienen we ook intern te kijken naar mogelijkheden om Data Flows te scripten. Dit om het proces te versnellen en om efficiënter te werken. Ik heb er alle vertrouwen in dat het Microsoft team de juiste keuzes gaat maken en ik kijk uit naar de volgende releases.
Bron: Valid | Foto: Valid
Zoals ieder jaar was het een voorrecht om CorporatiePlein te mogen organiseren. En de 2025-editie, de vijftiende van het…
www.corporatieplein.nl
CorporatieGids Magazine - November 2025 Inhoud Alfred van den Bosch en Frank Roerdinkholder (Vivare): Ambities waarmaken begint bij durven doen Remco…
Zoek en vind leveranciers en adviesbureaus die IT-diensten en oplossingen aanbieden aan woningcorporaties.